


Using Advanced Analytics and Continuous Active Learning to “Prove a Negative”
This is the second article in a two-part series that focuses on document review techniques for managing compliance in internal and regulatory investigations. Part 1 provided several steps for implementing an effective document review directed at achieving the objectives of a compliance investigation. This installment outlines an approach that can be used to demonstrate that there are no responsive documents to an equivalent statistical certainty – essentially proving a negative.
What Does it Mean to “Prove a Negative?”
The objective of a compliance investigation is most often to quickly locate the critical documents that will establish a cohesive fact pattern and provide the materials needed to conduct effective personnel interviews. In that situation, the documents are merely a means to an end.
Occasionally, however, the documents become an end unto themselves. For example, governmental agencies often use civil investigative demands (CIDs) to investigate allegations of potential statutory liability. In that context, the documents themselves become the object of the investigation. While those documents may well have downstream utility, the emphasis of the document review in responding to the CID is purely on locating any responsive documents.
There may well be situations where there simply are no responsive documents to be found. In practice, that typically means reviewing every single document in a given collection, just to come up empty handed. With modern electronically stored information (ESI) collections that total in the hundreds of thousands, or even millions, of documents, a linear review of that magnitude can be prohibitively expensive and time-consuming.
Alternatively, it is possible to leverage advanced analytics, continuous active learning and statistics to review only a fraction of an ESI collection, yet demonstrate that there are so few responsive documents potentially in the collection that a full-blown review would be entirely unreasonable. That is what is meant by proving a negative – undertaking an aggressive effort to locate responsive documents, finding none and using statistics to demonstrate the virtual absence of responsive documents.
Why Continuous Active Learning?
There are three principal technology-assisted review (TAR) protocols that can be used to enhance a document review: simple passive learning, simple active learning and continuous active learning. Because of the way these different protocols train the underlying TAR algorithms, only continuous active learning (CAL) protocols are effective in proving a negative.
As discussed in greater detail below, the objective in proving a negative is actually to make every possible effort to find responsive documents. So the technology-assisted review protocol should advance that objective.
The only TAR protocol that effectively seeks out responsive documents throughout the review process is CAL. A simple passive protocol trains by passing random documents to the reviewer. And a simple active protocol trains by a process known as uncertainty sampling, which provides the “gray” documents to the reviewer (i.e., the documents that are right at the border between documents that look to be responsive and those that look to be non-responsive).
By comparison, CAL primarily uses a process known as relevance feedback to pass training documents to the reviewer. Relevance feedback uses everything that is known about the documents coded to that point in time to select training documents that are most likely to be responsive.
Using a CAL protocol leverages the TAR algorithm. Every document reviewed in the process is a document that the algorithm sees as most likely to be responsive. That approach advances the objective of finding responsive documents far more efficiently than an approach that relies on random or gray documents and, therefore, CAL is critical to proving a negative.
Use Statistics to Scope the Review
The first step in proving a negative is to establish the statistical parameters that will set the margins of error for the review and, in turn, the number of documents that may have to be reviewed in the process. The expectation is that no responsive documents will ever be found, regardless of how many documents are reviewed. With that assumption, statistics will control the relationship between the number of documents reviewed and the margin of error – in other words, the number of responsive documents that might exist in the collection.
There is no hard-and-fast rule for setting the statistical boundaries. Rather, the decision depends on the relationship between the value of finding any responsive documents and the cost of obtaining these documents. In essence, the decision depends on some measure of proportionality and is likely going to be negotiated with the requesting party.
As an example, consider a collection of 500,000 documents that is not expected to contain a single responsive document. Using a binomial statistical calculator (such as the one at statpages.info/confint.html), the margins of error can be evaluated for samples of 1 percent, 2 percent, 5 percent and 10 percent of the collection to establish a range of alternatives:
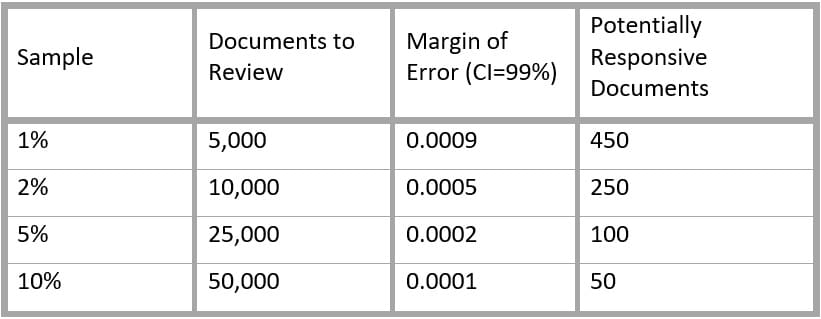
With a range of alternatives, the relative cost and benefit of various sample sizes can be evaluated, and the number of documents to be reviewed can be negotiated and set accordingly.
Use Analytics to Initiate a Review for Documents That Are “Close” to Responsive
The latent objective in proving a negative is actually to make every conceivable effort to locate the precise documents that are not expected to exist in the collection. That means truly exploiting every available analytical approach to locating responsive documents while keeping in mind that the TAR tool will eventually do the heavy lifting.
And, since no approach is likely to locate responsive documents (as none are expected to exist in the collection), the review should focus on finding documents that are contextually close to being responsive. These “close” documents will eventually serve as the best available training examples for the CAL review.
Start the process by using keyword searches that are carefully crafted to locate any responsive documents that might exist in the collection. And be sure to solicit any reasonable keyword searches from the requesting party. Doing so will not only enhance the potential for finding truly responsive documents, but also alleviate any concern on the part of the requesting party that the scope of the review might be too narrow. If a search returns too many documents, review a reasonable random sample across the entire hit population to establish a statistical absence of responsive documents.
Then, use advanced analytics to diligently explore specific components of the collection that are most likely to contain responsive documents. For example, keyword searches can be refined to focus on the documents held by specific key custodians. Communication analytics can be used to identify email exchange patterns that may be pertinent to the investigation. There may be certain file types (e.g., Microsoft Excel files or PowerPoint presentations) that are more likely to be responsive. Even associated metadata, like the original file path for a document, can be explored in a meticulous effort to find responsive documents.
This review should continue until all reasonable searches have been exhausted and between 20 percent and 30 percent of the total anticipated review effort has been completed. Doing so will initially establish the absence of responsive documents and provide a reasonable starting point for training the CAL algorithm. And these efforts should be recorded, should it be necessary to explain and justify the process down the line.
Use CAL in an Effort to Surface Any Truly Responsive Documents
Once the analytics review is complete, use continuous active learning to complete the remainder of the review. The CAL algorithm will efficiently analyze the entire collection to locate any documents that are contextually similar to “close” documents located during the analytics review and will continuously learn from every coding decision made along the way.
Optimize the CAL training regime from the analytics review with one or more synthetic seeds. Draft an electronic document that reflects the specific content of a document that would be considered responsive if it existed within the collection. Import the document into the collection, being careful to include some designation (such as a unique Bates identifier) that makes it easy to identify, and mark the synthetic seed as responsive. This will provide the continuous active learning algorithm with a very clear example of the precise language that makes a document responsive.
As with the keyword search process, a synthetic seed may be solicited from the requesting party as well. Doing so will ensure that the CAL algorithm will recognize, and elevate for review, documents that are contextually similar to specifically what the requesting party is seeking.
Make sure that some fraction of the documents reviewed during the CAL process are contextually diverse from the responsive synthetic seeds and the “close” documents identified in the analytics review. As discussed in the first article in this series, modern TAR tools include functionality directed at locating contextually diverse documents. This functionality is critical in proving a negative, as it ensures a thorough exploration of the entire collection.
Presumably, the CAL review will not locate any responsive documents, since they are not expected to exist within the collection. As with the analytics review, however, documents that are close to being responsive should be coded as positive in order to continuously surface any contextually similar documents and maximize the potential for finding truly responsive documents.
Use the Review and Statistics to “Prove a Negative”
Assuming no responsive documents have been located during the review, the underlying statistics can be used to essentially prove a negative. Obviously, without reviewing the entire collection, there is no way to be certain that it contains no positive documents. What can be said, however, is that there are a very limited number of responsive documents that might exist in the collection. From the above example, a review of 25,000 documents using this process would mean that there are likely no more than 100 responsive documents in the entire collection.
And, although that analysis is not based on a purely random statistical sample, this review process actually comprises a much more thorough effort to find positive documents. By using analytics and continuous active learning and by including contextually diverse documents in the CAL review, this process optimizes the likelihood of finding a responsive document in the collection, if one exists. Since no responsive documents have been found in the review, the likelihood that a responsive document exists elsewhere in the collection is, for all practical purposes, even less than if the review had been random.
Altogether, this process is a reasonable way to demonstrate the absence of responsive documents in a collection without having to review the entire collection and to do so in a way that is even more stringent than a random review.
 Thomas Gricks, Esq., is Managing Director, Professional Services at Catalyst. A prominent e-discovery lawyer and one of the nation's leading authorities on the use of TAR in litigation, Tom advises corporations and law firms on best practices for applying TAR technology to reduce the time and cost of discovery. He has more than 25 years of experience as a trial lawyer and in-house counsel, most recently with the law firm Schnader Harrison Segal & Lewis, where he was a partner and chair of the e-Discovery Practice Group.
Thomas Gricks, Esq., is Managing Director, Professional Services at Catalyst. A prominent e-discovery lawyer and one of the nation's leading authorities on the use of TAR in litigation, Tom advises corporations and law firms on best practices for applying TAR technology to reduce the time and cost of discovery. He has more than 25 years of experience as a trial lawyer and in-house counsel, most recently with the law firm Schnader Harrison Segal & Lewis, where he was a partner and chair of the e-Discovery Practice Group. 






