


A Much-Needed Intelligent Approach to Segmentation
Anti-money laundering (AML) is a complex and persistent challenge for financial institutions. AI is transforming key elements of the AML workflow and delivering an order of magnitude in performance improvements in the process.
Money laundering has become the leading source of compliance fines for North American and European institutions. In 2016 alone, regulators levied more than $42 billion in fines. The fines are increasingly commensurate with the flows. Each year, money-laundering transactions account for around $3 trillion. This equates to approximately 5 percent of the global GDP.
Even with these staggering numbers, only about 1 percent of illicit global financial flows are ever seized by the authorities.
Given the technology the industry has at its disposal and the stakes involved in the penalties, this shouldn’t be the case.
Ultimately, the current reality is a function of how the industry has attacked the AML problem to date. Today, banks attack it from the perspective of customer due diligence/KYC and the transaction level. The lever point, however, is with segmentation.
Segmentation is source of better AML outcomes.
Better is defined by lower false positives and lower false negatives, meaning that banks spend fewer resources and catch more bad actors.
While some sophisticated institutions practice segmentation today, many employ hand-coded rules or two-by-two blocks. As a result, these banks generate coarse segments that create bad scenarios and result in correspondingly high thresholds.
Recent advances in artificial intelligence transform the previously humble segmentation step into the most powerful and important element in the modern AML process – delivering order of magnitude improvements on false positives with minimal disruptions to existing systems while scaling to millions of transactions and maintaining exceptional transparency for model review boards and regulators alike.
A View of the Modern Segmentation Process
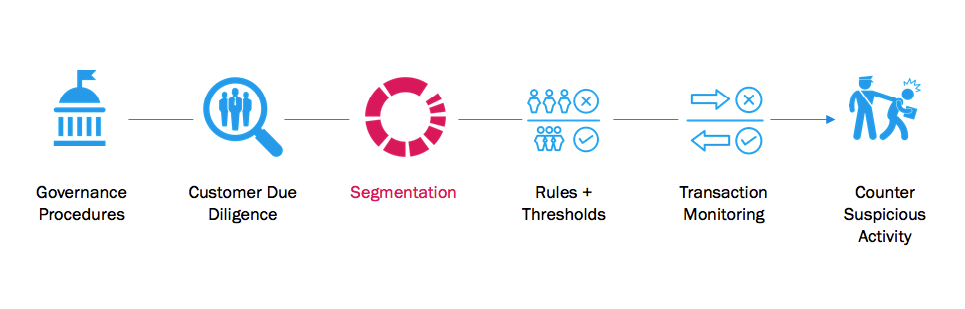
Governance and customer due diligence procedures have reached a high level of sophistication and, yet, the benefit of additional rules has had a marginal impact on detection. These procedures require a considerable amount of human time and subject matter expertise, and they have become standardized by regulators and the industry.
As the next step in an AML program, segmentation has tremendous downstream benefits. By appropriately segmenting customer and transaction data, important behavioral patterns can be observed. These behaviors are essential to set effective rules and thresholds that are used to flag transactions via the transaction monitoring systems.
While the segmentation process is open to change and improvement, the next step, transaction monitoring, is essentially locked down from an AML process perspective. All transaction monitoring system (TMS) providers must be vetted by government and independent agencies. As a result, the effectiveness of a TMS is a largely a function of what happens upstream of it.
Without strong segments, rules and thresholds, the TMS step leads to a high number of false positives and potentially misses authentic money-laundering attempts. High false positive rates ultimately negatively impact the investigation of suspicious activities, which is predominantly a human effort.
Industry Data Finds Vast Majority of AML Alerts Are False Positives
A recent industry survey of large financial institutions by PwC revealed that of the transaction alerts generated by banks’ current anti-money laundering detection efforts (most of which are hand-coded with, though a few rely on rudimentary data mining and statistical techniques), 90 to 95 percent of AML alerts were found to be false positives.
To complete due diligence reviews of the hundreds of thousands of alerts produced monthly under current AML detection programs, financial institutions must employ thousands of personnel (both internal and external) at a cost of hundreds of millions of dollars per year. Even a small decrease in the number of false positives generated, can save a firm millions of dollars while enhancing the overall efficacy of the program (meaning catching more bad guys).
Furthermore, there is well-documented research on the concept of alert fatigue. Delivering better cases will result in better investigations – creating a virtuous cycle for the investigative teams.
A select number of financial institutions have moved toward applying machine-learning-driven segmentation. While superior to hand-coded segments, machine-learning-driven segmentation practices struggle with some key challenges:
- The shortcomings of standard clustering methods such as K-means
- Segmenting client and transaction data separately
- Slow segment uptake into real-time transaction monitoring.
K-means is powerful algorithm, but in this context, it has some shortcomings: scalability is significantly limited, the number of clusters must be defined beforehand and it can be subject to chaining, resulting in highly non-uniform clusters (such as a single cluster).
Further, combining client data with multiple types of transaction data builds a high dimensional data set that is not well served by the aforementioned techniques. For example, many databases cannot store more than 2,000 columns. As a result, clustering high-dimensional datasets becomes very difficult and results in an artificially low number of features. By not incorporating the entire dataset, many patterns and anomalies can go undetected.
Finally, even after segments have been defined, the subjective nature of segment assignment often creates lengthy discussions on the best fit for customers or transactions that are new or not well-understood. After this, it takes significant lead time for IT teams to update the appropriate TMSs with updated segments, rules and thresholds.
Where Intelligent Segmentation Comes In
Intelligent segmentation combines unsupervised learning with supervised learners in an application that powers the categorization of customer data into segments/groups with similar characteristics so that appropriate rules and thresholds can be determined to flag suspicious transactions.
Intelligent segmentation uses unsupervised learning approaches encapsulated in Topological Data Analysis (TDA), a technique developed in Stanford’s mathematics department with funding from DARPA and the National Science Foundation (NSF).
TDA and machine learning automatically assemble self-similar groups of customers and customers-of-customers. AI software makes the selection of the appropriate algorithms to create candidate groups and tune the scenario thresholds within those groups until the optimal ones are identified. These groups are then put through a tuning process with additional algorithms to identify optimal groupings. A subject matter expert then adjusts the segmentation process per their specifications.
The next step uses supervised learning to predict future behaviors that allow subject matter experts to create new rules and thresholds that accurately detect potential launderers.
Justification is a Critical Component for the Financial Services Industry
None of this work is useful if it cannot be explained. As a result, these new approaches generate a complete model, decision tree, audit trail and documentation for internal review teams to discuss and justify segments, with the ability to adjust segments as needed. These tools facilitate compliance efforts and regulatory review.
The key, however, is not to produce a model as your output. Models have limited utility. Intelligent segmentation goes to market as an application that has the ability to apply segments to scenario analysis to create appropriate rules and thresholds and to then seamlessly push this information to relevant transaction-monitoring systems.
Finally, the intelligent segmentation application needs to learn from new and updated data sources so that it can keep pace with the changing behavior of criminals.
Summary
Financial crimes are not victimless. They fund terrorism, human trafficking and other crimes against humanity. At the center of the financial crimes portfolio sits a persistent data problem – one defined by quality, sparsity and dimensionality.
Financial institutions need to attack this problem from a different angle if they hope to solve this moral and economic challenge. That angle is segmentation, and specifically an intelligent segmentation approach that includes the predictive model, the UX of the application, the justification of the segments and the integration with transaction-monitoring systems. By applying artificial intelligence to the AML problem, financial institutions can dramatically enhance their risk profiles while simultaneously reducing their operating costs.
 Gurjeet Singh is Ayasdi's executive chairman and co-founder. He leads a technology movement that emphasizes the importance of extracting insight from data, not just storing and organizing it.
Singh developed key mathematical and machine-learning algorithms for Topological Data Analysis (TDA) and their applications during his tenure as a graduate student in Stanford’s mathematics department, where he was advised by Ayasdi co-founder Professor Gunnar Carlsson.
He is the author of numerous patents and has been published in a variety of top mathematics and computer-science journals. Before starting Ayasdi, he worked at Google and Texas Instruments. Singh was named by Silicon Valley Business Journal as one of their “40 Under 40” in 2015.
He holds a B.Tech. degree from Delhi University, and a Ph.D. in Computational Mathematics from Stanford University. He lives in Palo Alto with his wife and two children and develops multi-legged robots in his spare time.
Gurjeet Singh is Ayasdi's executive chairman and co-founder. He leads a technology movement that emphasizes the importance of extracting insight from data, not just storing and organizing it.
Singh developed key mathematical and machine-learning algorithms for Topological Data Analysis (TDA) and their applications during his tenure as a graduate student in Stanford’s mathematics department, where he was advised by Ayasdi co-founder Professor Gunnar Carlsson.
He is the author of numerous patents and has been published in a variety of top mathematics and computer-science journals. Before starting Ayasdi, he worked at Google and Texas Instruments. Singh was named by Silicon Valley Business Journal as one of their “40 Under 40” in 2015.
He holds a B.Tech. degree from Delhi University, and a Ph.D. in Computational Mathematics from Stanford University. He lives in Palo Alto with his wife and two children and develops multi-legged robots in his spare time. 







